2026. 2. 3. 12:58ㆍ개발
Outbox + CQRS + Projection으로 “조인 지옥”을 줄이는 Mini CDC 구현기 (StackOps)
운영/대시보드/검색 화면은 “빠르게 읽기”가 핵심이고, 재고/상품 같은 도메인 데이터는 “정확하게 쓰기”가 핵심입니다. 시간이 지날수록 이 두 요구가 충돌하면서, 읽기 API에 조인이 늘어나고 성능과 복잡도가 같이 증가합니다.
이 글에서는 StackOps 프로젝트에서 Outbox 기반 CDC + CQRS(Write/Read 분리) + Projection(Read Model) 구조를 직접 구현하면서 어떤 선택을 했고, 운영 내구성을 위해 어떤 장치를 넣었는지 정리합니다.
1) 목표와 핵심 아이디어
- Write Model(정규화 DB)은 트랜잭션/무결성 중심으로 유지
- Write 변경을 Outbox 이벤트로 표준화하여 “변경”을 외부로 전달
- Projection(Read Model)을 별도로 유지하고, 조회 API는 이를 join-less로 읽기
핵심: “쓰기 DB 변경을 이벤트로 표준화(Outbox)하고, 읽기 모델(Projection)을 별도로 유지해서 조회를 단순화한다.”
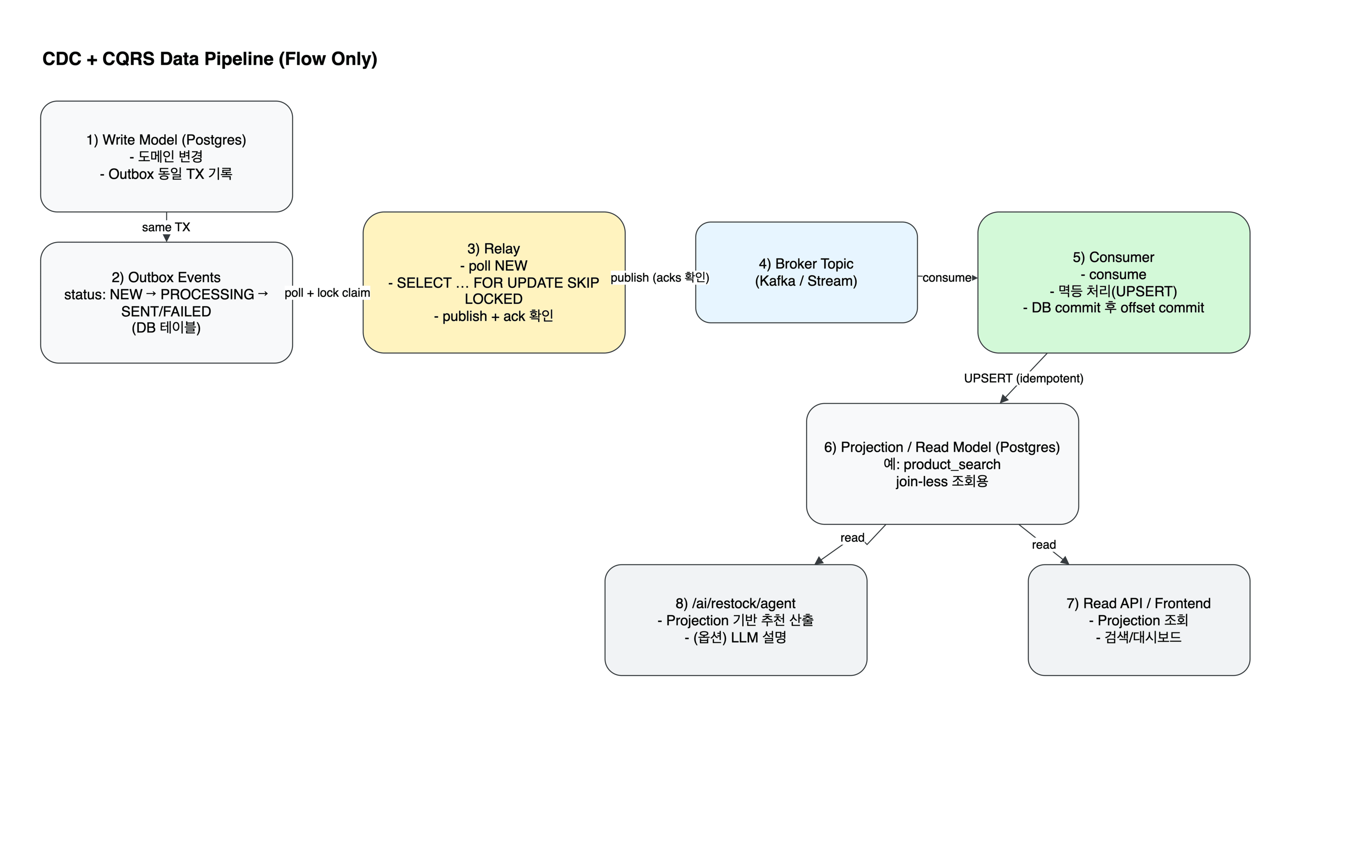
2) CDC / CQRS 파이프라인 개요
전체 흐름은 아래와 같습니다.
- Write Model(Postgres)에서 도메인 변경과
outbox_events를 동일 트랜잭션으로 커밋 - Relay가 Outbox를 poll 하며
FOR UPDATE SKIP LOCKED로 작업 선점 → 상태 전이 - Relay가 이벤트를 Kafka Topic으로 발행(필요 시 DLQ 토픽으로 분기)
- Consumer가 이벤트를 consume → Projection(Read Model)을 멱등 UPSERT로 갱신
- API/UI는 Projection을 join-less로 빠르게 조회
3) Outbox가 필요한 이유 (이벤트 일관성)
CDC에서 가장 위험한 불일치 케이스는 아래 둘입니다.
- DB는 커밋됐는데, 이벤트 발행이 실패 → 읽기 모델이 뒤쳐짐
- 이벤트는 발행됐는데, DB는 롤백 → 잘못된 변경이 전파됨
Outbox 패턴은 “DB 커밋과 이벤트 기록”을 같은 트랜잭션으로 묶어, 원천(Source of truth)을 Write DB로 고정하는 방식입니다. Relay는 outbox 테이블을 안전하게 읽어 이벤트를 발행하기 때문에, “DB는 됐는데 이벤트가 없음” 같은 불일치 리스크를 줄일 수 있습니다.
4) Relay 설계: 동시성 선점 + Ack 확인 + 재시도/격리
Relay는 단순 publisher가 아니라, 운영 내구성을 만드는 컴포넌트입니다. StackOps에서는 다음을 핵심으로 둡니다.
- 락 기반 선점: 다중 Relay 환경에서도 중복 처리 방지
- Ack 확인 후 SENT: 브로커에 “확정적으로 들어갔을 때만” outbox 상태를 SENT로 변경
- 재시도 + DLQ: 실패 누적 시 FAILED로 격리하고, 선택적으로 DLQ 토픽으로 전달
4-1) Relay 핵심 코드 (중요 부분만)
# relay.py (핵심만 발췌)
KAFKA_BOOTSTRAP = os.getenv("KAFKA_BOOTSTRAP", "localhost:9092")
KAFKA_TOPIC = os.getenv("KAFKA_TOPIC", "product-events")
KAFKA_DLQ_TOPIC = os.getenv("KAFKA_DLQ_TOPIC", "product-events-dlq")
MAX_RETRY = int(os.getenv("RELAY_MAX_RETRY", "5"))
BATCH_SIZE = int(os.getenv("RELAY_BATCH_SIZE", "10"))
POLL_INTERVAL_SEC = float(os.getenv("RELAY_POLL_INTERVAL_SEC", "1.0"))
def make_producer() -> KafkaProducer:
# acks=all + fut.get()로 "진짜 들어갔는지" 확인하는 구성이 핵심
return KafkaProducer(
bootstrap_servers=KAFKA_BOOTSTRAP,
value_serializer=lambda v: json.dumps(v, ensure_ascii=False).encode("utf-8"),
key_serializer=lambda k: str(k).encode("utf-8"),
acks="all",
retries=3,
linger_ms=10,
request_timeout_ms=10000,
max_block_ms=10000,
)
# 1) NEW 이벤트를 잠금 걸고 가져오기 (선점)
stmt = (
select(OutboxEvent)
.where(OutboxEvent.status == "NEW")
.order_by(OutboxEvent.id.asc())
.limit(BATCH_SIZE)
.with_for_update(skip_locked=True) # ⭐ 다중 Relay에서도 중복 처리 방지
)
events = db.execute(stmt).scalars().all()
# 2) send + ACK 확인 후에만 SENT 처리
for ev in events:
fut = producer.send(
KAFKA_TOPIC,
key=ev.aggregate_id,
value={
"outboxId": ev.id,
"ownerId": ev.owner_id,
"aggregateType": ev.aggregate_type,
"aggregateId": ev.aggregate_id,
"eventType": ev.event_type,
"payload": ev.payload_json,
"createdAt": ev.created_at.isoformat() if ev.created_at else None,
},
)
try:
fut.get(timeout=10) # ⭐ 브로커에 확정적으로 들어갔는지 확인
ev.status = "SENT"
ev.published_at = datetime.now()
ev.retry_count = 0
ev.last_error = None
except Exception as e:
ev.retry_count += 1
ev.last_error = str(e)
# 3) 재시도 누적 시 FAILED 격리 + (선택) DLQ로 전달
if ev.retry_count >= MAX_RETRY:
ev.status = "FAILED"
# push_to_dlq(producer, ev) # 선택적으로 DLQ 토픽 전송
else:
ev.status = "NEW"
db.commit()
여기서 중요한 포인트는 fut.get()으로 ACK를 확인한 뒤에만 outbox 상태를 SENT로 바꾼다는 점입니다. send 호출만으로 “전달 성공”을 가정하면, 네트워크/브로커 이슈에서 데이터 유실로 이어질 수 있습니다.
5) Consumer 설계: 멱등 UPSERT + 커밋 순서
이벤트 기반 파이프라인은 기본적으로 at-least-once 소비(중복 가능성)를 염두에 두는 것이 안전합니다. 그래서 Consumer는 “중복/재처리에도 결과가 같도록” 아래 두 가지가 핵심입니다.
- 멱등 처리: Projection 갱신을 UPSERT로 수행
- 커밋 순서: DB commit 성공 후에만 offset commit
5-1) Consumer 핵심 코드 (중요 부분만)
# consumer.py (핵심만 발췌)
consumer = KafkaConsumer(
KAFKA_TOPIC,
bootstrap_servers=KAFKA_BOOTSTRAP,
group_id=CONSUMER_GROUP,
auto_offset_reset="earliest",
enable_auto_commit=False, # ⭐ 자동 커밋 금지 (커밋 순서 통제)
value_deserializer=lambda v: json.loads(v.decode("utf-8")),
key_deserializer=lambda k: k.decode("utf-8") if k else None,
)
def upsert_product_search(db, owner_id: int, payload: dict):
# ⭐ ON CONFLICT DO UPDATE로 멱등성 확보
sql = text("""
INSERT INTO product_search (product_id, owner_id, name, category, price, qty, is_deleted, deleted_at, updated_at)
VALUES (:product_id, :owner_id, :name, :category, :price, :qty, FALSE, NULL, NOW())
ON CONFLICT (product_id) DO UPDATE
SET
name = EXCLUDED.name,
category = EXCLUDED.category,
price = EXCLUDED.price,
qty = EXCLUDED.qty,
is_deleted = FALSE,
deleted_at = NULL,
updated_at = NOW()
""")
db.execute(sql, {...})
for msg in consumer:
value = msg.value
payload = value["payload"]
owner_id = value["ownerId"]
event_type = value.get("eventType")
db = SessionLocal()
try:
if event_type == "PRODUCT_DELETED":
soft_delete_product_search(db, owner_id, payload)
elif event_type == "STOCK_ADJUSTED":
apply_stock_adjusted(db, owner_id, payload)
else:
upsert_product_search(db, owner_id, payload)
db.commit() # ⭐ 1) DB 반영이 먼저
consumer.commit() # ⭐ 2) 그 다음 offset commit
except Exception as e:
db.rollback()
time.sleep(1.0)
finally:
db.close()
DB commit → offset commit 순서를 지키면, 처리 중 장애가 나도 “재처리”로 복구됩니다. 반대로 offset을 먼저 커밋하면, DB 반영 실패 시 메시지가 유실될 수 있습니다.
6) DLQ Publisher: 실패 이벤트의 격리와 추적
Relay 단계에서 재시도를 모두 소진한 이벤트는 outbox에서 FAILED로 격리됩니다. 운영 관점에서는 “왜 실패했는지 추적 가능한 채널”이 필요하고, 이를 위해 DLQ 토픽으로 실패 이벤트를 별도로 내보낼 수 있습니다.
6-1) DLQ Publisher 핵심 코드 (중요 부분만)
# dlq_publisher.py (핵심만 발췌)
# FAILED 이벤트를 가져와서 DLQ 토픽으로 보내고, 성공하면 DLQ_SENT로 상태 변경
stmt = (
select(OutboxEvent)
.where(OutboxEvent.status == "FAILED")
.order_by(OutboxEvent.id.asc())
.limit(BATCH_SIZE)
.with_for_update(skip_locked=True)
)
events = db.execute(stmt).scalars().all()
for ev in events:
try:
fut = producer.send(
KAFKA_DLQ_TOPIC,
key=ev.aggregate_id,
value={
"outboxId": ev.id,
"eventType": ev.event_type,
"aggregateType": ev.aggregate_type,
"aggregateId": ev.aggregate_id,
"payload": ev.payload_json,
"retryCount": ev.retry_count,
"lastError": ev.last_error,
"failedAt": datetime.now().isoformat(),
},
)
fut.get(timeout=10)
ev.status = "DLQ_SENT" # ⭐ DLQ 전달 성공 시 상태 변경
except Exception as e:
# DLQ 전송 실패 시 FAILED 유지 (다음 루프에 재시도)
ev.last_error = f"{ev.last_error} | DLQ_PUB_ERR={str(e)}"
db.commit()
7) DB 세션/의존성: FastAPI에서의 안전한 트랜잭션 처리
애플리케이션 레이어에서 DB 세션을 일관되게 관리하는 것도 운영 안정성에 중요합니다. StackOps에서는 FastAPI dependency로 DB 세션을 공급하며, 예외 발생 시 rollback을 보장합니다.
7-1) DB 세션 핵심 코드
# db.py (그대로 사용해도 되는 핵심 구성)
engine = create_engine(
DATABASE_URL,
pool_pre_ping=True, # 연결 죽었으면 자동 감지
echo=False,
)
SessionLocal = sessionmaker(
bind=engine,
autoflush=False,
autocommit=False,
)
def get_db():
db = SessionLocal()
try:
yield db
except Exception:
db.rollback()
raise
finally:
db.close()
8) 정리: 이 구조가 해결하는 것
- 조회 단순화: Projection(Read Model)로 join-less 조회
- 이벤트 일관성: Outbox(동일 트랜잭션 기록) + Relay polling
- 운영 내구성: SKIP LOCKED 선점 + 재시도/상태 머신 + DLQ 격리
- 재처리 안전성: Consumer 멱등 UPSERT + commit 순서 보장
“Exactly-once”를 시스템 전체에서 보장하기보다,
at-least-once + 멱등 + 올바른 커밋 순서로 운영 내구성을 확보하는 접근을 선택했습니다.
Appendix) 다음 개선 포인트
- stuck PROCESSING 복구: 일정 시간 초과 이벤트를 NEW로 되돌리는 reaper 추가
- 대량 변경 최적화: Consumer batch consume + bulk upsert 도입
- 스키마 계약: event_type별 payload 스키마 버저닝/검증
끝.
'개발' 카테고리의 다른 글
| 나만의 무기 4편 - 회고 (2) | 2025.07.31 |
|---|---|
| 나만의 무기 3편 – AI 평어 노래 맞추기 게임 & 빠른대전 (3) | 2025.07.30 |
| 나만의 무기 2편 – 기획 아이디어 (3) | 2025.07.30 |
| 나만의 무기 1편: 개발 보다 더 어려운 기획 회의 (1) | 2025.07.30 |
| Pintos VM Project - merge-mm / stk / pa 테스트 트러블슈팅 정리 (0) | 2025.06.15 |